딥러닝의 기본 개념인 인공신경망에 대해서 개략적으로 알아보고 그에 대해서 정리한 글
목차
인공신경망

정보 처리하고자 함수를 인간의 뇌로 처리로 해보자는 개념에서 출발
→ 뇌는 여러 뉴런들의 조합으로 처리되고 있음.
퍼셉트론
1.1. 단층 퍼셉트론
단일 뉴런 : 수상돌기를 통해 입력신호를 받고 이 신호를 축삭돌기를 통해 뉴런으로 신호를 보냄.
→ 이를 수학적으로 만들 모델이 단층 퍼셉트론
- 입력 변수들을 선형결합
- 선형결합 값의 변환한 후 이를 전달 (Activiation Function을 통해 변환)
Activitaion Function (선형 또는 비선형으로 전)
이는 정보를 얼만큼 다음 레이어로 전달할지를 결정하는 함수
→ 단층만으로는 복잡한 모델에 대한 해석이 불가
→ 이를 퍼셉트론을 늘려서 해결.
1.2. 다층 퍼셉트론
입력 데이터를 히든 레이어로 전달
히든레이어에는 여러 가지의 활성함수가 존재
이를 다시 선형으로 합성해서 out layer로 전달
→ hidden layer가 늘어나면서 복잡해짐
→ 딥러닝의 기본 구
다층 퍼셉트론의 학습
1. 비용함수 또는 목적함수 정의
2. 비용함수 또는 목적함수를 이용해 최적화 문제로 변환
3. 최적화 문제 풀기
→ 추정해야 할 모델의 파라미터가 비선형 결합 형태로 되어 있음.
근사해를 구해야 함.
경사하강법
오차역전파
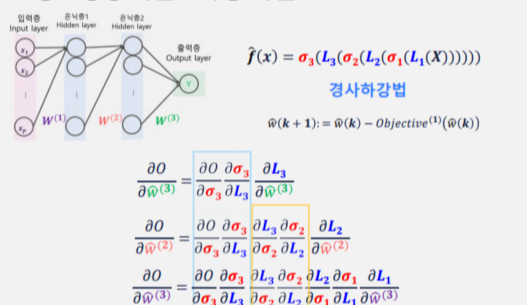
합성함수의 꼴로 나타나므로 규칙적으로 미분되는 꼴이 나타남.
Theano/tesorflow/torch 등의 라이브러리는 gradient를 간편하게 계산해주는 기능을 포함
반복적으로 나타는 부분은 프로그래밍 시 효율적으로 처리하는 걸 생각해야 함.
→ 이제 미분을 반복해서 시행하여 경사하강법을 진행하는게 인공신경망 학습의 방법
◆ 오차역전파
비용 함수의 가중치에 대한 기울기를 수치 미분으로 계산하는 건 시간이 너무 오래 걸림
→ 비용 함수 편미분 기울기를 순전파의 반대 방향으로 전파
chain rule을 통해 국소 미분으로 분해하는 계산하는 방식!
이슈 1. 속도
인공신경망 학습이 속도가 느림.
계산복잡도 이슈!
해결방법
- 배치경사하강법(BGD)
- 모든 훈련 데이터를 이용해서 필요한 계산을 다하고 업데이트
- 확률적 경사하강법(SGD)
- 확률적으로 선택된 하나의 예로 필요한 계산을 다하고 업데이트 시키는 방법.
- 미니배치 경사하강법(MBGD)
- 배치크기 훈련 데이터를 이용해서 필요한 계산을 다하고 업데이트 시키는 방법
- 보통 default로 사용
이슈 2. 경사하강법
gradient가 0에 도달하면 더 이상 업데이트가 되지 않는다.
하지만 gradient가 0이라고 해서 거기가 최소지점이라고는 얘기할 수 없다.
→ 적절한 학습률 선정
→ 다양한 경사하강법이 나타남.
인공 신경망 여러 학습 이슈
이슈 1. 기울기 소실(Vanishing Gradinet)
layer가 많아질수록 chain rule에 의해 여러번 미분하게 됨.
이 결과 값이 0에 가까워지는 현상이 발생
즉 input layer근처의 데이터는 거의 학습이 되지 않는 현상을 말함.
해결방법
- sigmoid tanh 이외에 다른 활성함수를 활용
이슈 2. 과소적합과 과대적합 (Overfitting/Underfitting)
과소적합 : 학습이 부족해서 error가 매우 큼
- ex. vanishing Gradient로 학습이 부족한 경우
과적합 : error가 너무 적어서 다른 데이터셋이 들어오면 인식을 못하는 문제
- 모델이 너무 복잡한 경우
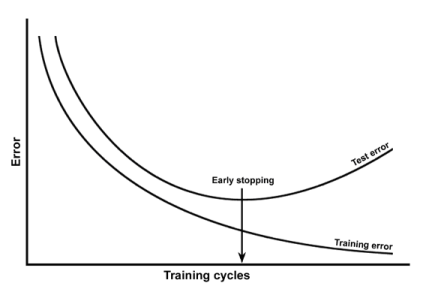
과적합 방지
1. 정규화 (Regularization)
- 비용함수 정의할때 Regularization을 추가
- Regularization : 특정 변수에 대해 파라미터(가중치) 값을 줄여서 영향도를 줄이는 역할
2. 드롭아웃(Drop out)
- 학습 과정에서 일부러 특정 노드들에 연결된 가중치들은 업데이트를 하지 말자
- 어떤 노드를 업데이트시키지 않을 것인가를 무작위로 그때그따 바꿔 가며 결
3. 데이터 증강 (Data Augmentation)
- 너무 적은 데이터셋을 통해 과적합이 되는거라면 데이터를 일부로 쪼개거나 약간 변형을 해줘서 증
마무리
큰 구조를 상시 파악하는게 중요!
'데이터' 카테고리의 다른 글
| [데이터 모델링 및 평가] 군집 분석 및 앙상블 방법론 내용 정리 (0) | 2023.04.03 |
|---|---|
| [데이터 모델링 및 평가] 의사결정 나무(Decision Tree) 내용 정리 (0) | 2023.04.03 |
| [데이터 모델링 및 평가] 분류 모델 - KNN, SVM 내용 정리 (0) | 2023.04.03 |
| [데이터 모델링 및 평가] 정규화 선형 모델 정리 (0) | 2023.04.03 |
| [데이터 전처리] [Python] 데이터 처리 기초 내용 정리 (문자열, 시계) (0) | 2023.04.01 |




댓글